
今天继续带大家学习大数据。今天主要介绍大数据价值链的数据存储部分,前面两期重点介绍了数据生成和数据获取,有希望学习的朋友可以翻阅我前面的文章。希望大家持续学习,每天关注,我会连续更新文章,让大家系统学习和认识大数据。

阶段III:数据存储
大数据系统中的数据存储子系统将收集的信息以适当的格式存放以待分析和价值提取。为了实现这个目标,数据存储子系统应该具有如下两个特征:
•存储基础设施应能持久和可靠地容纳信息;
•存储子系统应提供可伸缩的访问接口供用户查询和分析巨量数据。从功能上,数据存储子系统可以分为硬件基础设施和数据管理软件。

一、存储基础设施
硬件基础设施实现信息的物理存储,可以从不同的角度理解存储基础设施。首先,存储设备可以根据存储技术分类。典型的存储技术有如下几种。
•随机存取存储器(RAM):是计算机数据的一种存储形式,在断电时将丢失存储信息。现代RAM包括静态RAM、动态RAM和相变RAM。

•磁盘和磁盘阵列:磁盘是现代存储系统的主要部件。HDD由一个或多个快速旋转的碟片构成,通过移动驱动臂上的磁头,从碟片表面完成数据的读写。与RAM不同,断电后硬盘仍能保留数据信息,并且具有更低的单位容量成本,但是硬盘的读写速度比RAM读写要慢得多。由于单个高容量磁盘的成本较高,因此磁盘阵列将大量磁盘整合以获取高容量、高吞吐率和高可用性。
•存储级存储器:是指非机械式存储媒体,如闪存。闪存通常用于构建固态驱动器SSD,SSD没有类似HDD的机械部件,运行安静,并且具有更小的访问时间和延迟。但是SSD的单位存储成本要高于HDD。
这些存储设备具有不同的性能指标,可以用来构建可扩展的、高性能的大数据存储子系统。

其次,可以从网络体系的观点理解存储基础设施,存储子系统可以通过不同的方式组织构建。
•直接附加存储(DAS):存储设备通过主机总线直接连接到计算机,设备和计算机之间没有存储网络。DAS是对已有服务器存储的最简单的扩展。
•网络附件存储(NAS):NAS是文件级别的存储技术,包含许多硬盘驱动器,这些硬盘驱动器组织为逻辑的冗余的存储容器。和SAN相比,NAS可以同时提供存储和文件系统,并能作为一个文件服务器。
•存储区域网络(SAN):SAN通过专用的存储网络在一组计算机中提供文件块级别的数据存储。SAN能够合并多个存储设备,例如磁盘和磁盘阵列,使得它们能够通过计算机直接访问,就好象它们直接连接在计算机上一样。
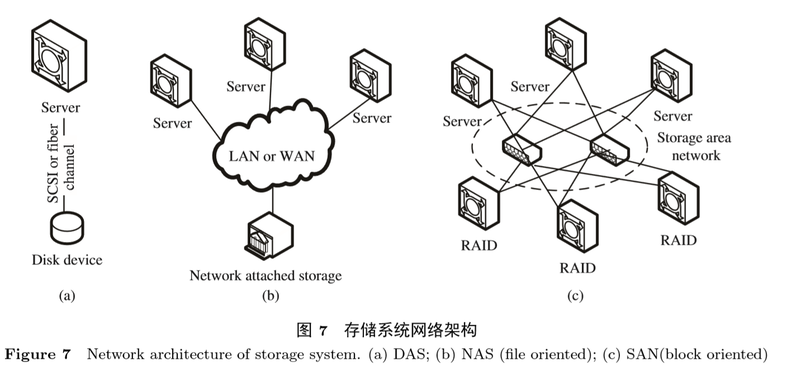
这三种存储技术的存储网络体系架构如图7所示,SAN具有最复杂的网络架构,并依赖于特定的存储网络设备。
最后,尽管已有的存储系统架构得到了深入的研究,但是却无法直接应用于大数据系统中。为了适应大数据系统的“4Vs”特性,存储基础设施应该能够向上和向外扩展,以动态配置适应不同的应用。
一个解决这些需求的技术是云计算领域提出的存储虚拟化。存储虚拟化将多个网络存储设备合并为单个存储设备。目前可以在SAN和NAS架构上实现存储虚拟化。基于SAN的存储虚拟化在可扩展性、可靠性和安全方面能够比基于NAS的存储虚拟化具有更高的性能。但是SAN需要专用的存储基础设施,从而带来较高的成本。

二、数据管理框架
数据管理框架解决的是如何以适当的方式组织信息以待有效地处理。在大数据出现之前,数据管理框架就得到了较为广泛的研究。从层次的角度将数据管理框架划分为3层: 文件系统、数据库技术和编程模型, 如图 8 所示。
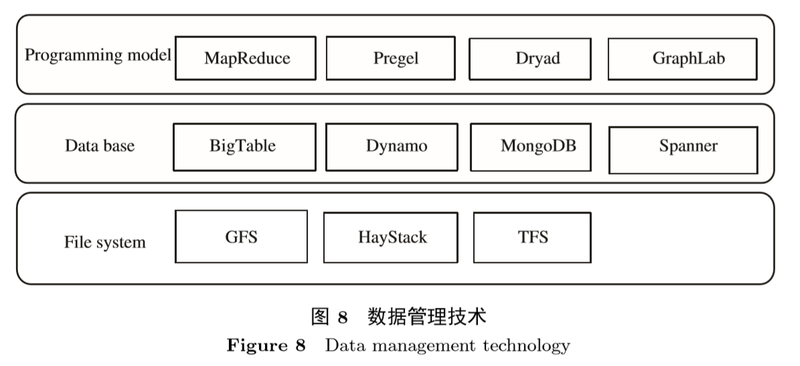
(1) 文件系统
文件系统是大数据系统的基础,因此得到了产业界和学术界的广泛关注。Google为大型分布式数据密集型应用设计和实现了一个可扩展的分布式文件系统GFS。GFS运行在廉价的商用服务器上,为大量用户提供容错和高性能服务。GFS适用于大文件存储和读操作远多于写操作的应用。但是GFS具有单点失效和处理小文件效率低下的缺点,Colossus改进了GFS并克服了这些缺点。此外,其他的企业和研究者们开发了各自的文件存储解决方案以适应不同的大数据存储需求。

(2)数据库技术
数据库技术已经经历了30多年的发展,不同的数据库系统被设计用于不同规模的数据集和应用。传统的关系数据库系统难以解决大数据带来的多样性和规模的需求。由于具有模式自由、易于复制、提供简单API、最终一致性和支持海量数据的特性,NoSQL数据库逐渐成为处理大数据的标准。随后将根据数据模型的不同,讨论三种主流的NoSQL数据库:键值(key-value)存储数据库、列式存储数据库和文档存储数据库。
(a)键值存储数据库
键值存储是一种简单的数据存储模型,数据以键值对的形式储存,键是唯一的。近年出现的键值存储数据库受到Amazon公司的Dynamo影响特别大。在Dynamo中,数据被分割存储在不同的服务器集群中,并复制为多个副本。可扩展性和持久性依赖于以下两个关键机制。

•分割和复制:Dynamo的分割机制基于一致性哈希技术,将负载分散在存储主机上。哈希函数的输出范围被看作是一个固定的循环空间或“环”。系统中的每个节点将随机分配该空间中的一个值,表示它在环中的位置。通过哈希标识数据项的键,可以获得该数据项在环中对应的节点。Dynamo系统中每条数据项存储在协调节点和N−1个后继节点上,其中N是实例化的配置参数。如图9所示,节点B是键k的协调节点,数据存储在节点B同时复制在节点C和D上。此外,节点D将存储在(A,B],(B,C]和(C,D]范围内的键。
•对象版本管理:由于每条唯一的数据项存在多个副本,Dynamo允许以异步的方式更新副本并提供最终一致性。每次更新被认为是数据的一个新的不可改变的版本。一个对象的多个版本可以在系统中共存。
(b)列式存储数据库
列式存储数据库以列存储架构进行存储和处理数据,主要适合于批量数据处理和实时查询。下面介绍典型的列式存储系统。
•Bigtable:是Google公司设计的一种列式存储系统。Bigtable基本的数据结构是一个稀疏的、分布式的、持久化存储的多维度排序映射,映射由行键、列键和时间戳构成。行按字典序排序并且被划分为片,片是负载均衡单元。列根据键的前缀成组,称为列族,是访问控制的基本单元。时间戳则是版本区分的依据。
•Cassandra:由Facebook开发并于2008年开源,结合了Dynamo的分布式系统技术和Bigtable的数据模型。Cassandra中的表是一个分布式多维结构,包括行、列族、列和超级列。此外,Cassandra的分割和复制机制也和Dynamo的类似,用于确保最终一致性。
•Bigtable改进:由于Bigtable不是开源的,因此开源项目HBase和Hypertable进行合并,同时吸收了Bigtable的思想,实现了类似的系统。
列式存储数据库大部分是基于Bigtable的模式,只是在一致性机制和一些特性上有差异。

(c)文档数据库
文档数据库能够支持比键值存储复杂得多的数据结构。MongoDB,SimpleDB和CouchDB是主要的文档数据库,它们的数据模型和JSON对象类似。不同文档存储系统的区别在于数据复制和一致性机制方面。
(d)其他NoSQL和混合数据库

除了前面提到的数据存储系统,还有许多其他项目支持不同的数据存储系统。

(3)编程模型
尽管NoSQL数据库具有很多关系型数据库不具备的优点,但是没有插入操作的声明性表述,对查询和分析的支持也不够。编程模型则对实现应用逻辑和辅助数据分析应用至关重要。但是,使用传统的并行模型如OpenMP和MPI在大数据环境下实现并行编程非常困难。
许多并行编程模型已被提出应用于领域相关的应用。这些模型有效地提高了NoSQL数据库的性能,缩小了NoSQL和关系型数据库性能的差距,因此NoSQL数据库逐渐成为海量数据处理的核心技术。目前主要有三种编程模型:通用处理模型、图处理模型以及流处理模型。
•通用处理模型
这种类型的模型用于解决一般的应用问题,被用于MapReduce和Dryad中。其中,MapReduce是一个简单但功能强大的编程模型,能将大规模的计算任务分配到大的商用PC集群中并行运行。
•图处理模型
社交网络分析和RDF等能够表示为实体间的相互联系,因此可以用图模型来描述。和流类型(flow-type)的模型相比,图处理的迭代是固有的,相同的数据集将不断被重访。
•流处理模型
S4和Storm是两个运行在JVM上的分布式流处理平台。S4实现了actor编程模型,每个数据流中keyedtupple被看作是一个事件并被以某种偏好路由到处理部件。PEs形成一个有向无环图,并且处理事件和发布结果。处理节点是PEs的逻辑主机并能监听事件,将事件传递到处理单元容器PEN中,PEN则以适当的顺序调用处理部件。Storm和S4有着许多相同的特点。Storm作业同样由有向无环图表示,它和S4的主要区别在于架构:S4是分布式对称架构,而Storm是类似于MapReduce的主从架构。

上表比较了上述几种编程模型的特点。
首先,尽管实时处理越来越重要,批处理仍然是重要的数据处理方式。
其次,大多数系统采取图作为编程模型是因为图能够表示更复杂的任务。
再次,所有的系统都支持并发执行以加速处理速度。
第四,流处理模型使用内存作为数据存储媒体以获得高访问和处理速率,而批处理模型使用文件系统或磁盘存储海量数据以支持多次访问。
第五,这些系统的架构通常是主–从式的,但是S4则是分布式的架构。
最后,不同的系统具有不同的容错策略。对于Storm和S4,当节点失效时,失效节点的任务将转移到备用节点运行;Pregel和GraphLab则是用检查点用于容错;MapReduce和Dryad则仅指出节点级别的容错。

今天介绍了大数据价值链的数据存储部分,后面会继续带你认识不一样的大数据。


